Ensuring optimal performance when using Sigma on top of large datasets comes with some best practices. First, what constitutes a large dataset is dependent on aspects such as warehouse size, the use case, and the intended workbook load time or performance. Often datasets that require performance to be improved are 100+ million rows, or have more than 30 columns. Let’s look at the easiest ways to achieve the greatest lift when it comes to performance improvement and optimization.
Of course, a data schema or structure properly tuned for your use cases and specific cloud data warehouse is always suggested. Since data tuning and optimization procedures like setting correct clustering keys and warehouse sizing may require work from a data specialist in your organization — and are use case dependent — we will consider those as additional optimization techniques that won’t be covered here.
The sections below are ordered in terms of possible greatest lift to performance. I suggest you implement the suggestions below starting at the top and going down the list.
Sigma Materialization
On columnar databases, data operations such as joining, aggregating, sorting, and filtering can have significant impacts on performance. Joining tables can have an especially significant impact when a large number of columns or rows are involved.
The easiest way to improve performance is to utilize Sigma materialization. Materialization can be used on any Sigma Dataset built on a connection with write access enabled. Materialization takes the query Sigma generates for a dataset and writes it as a single new table in your database. Additionally, Sigma updates the table with new data based on the refresh schedule you set on the materialization. What this means is that Sigma is now querying a single table, in which expensive operations, such as joins are already completed rather than trying to accomplish them on the fly. Keep in mind that the data in a materialized dataset is only as live as the last time that the refresh has been run on the materialization. If your data is updated frequently, maybe continuously or multiple times an hour, and your use case requires the most up-to-date data, materialization may not be a good option for you.
Best Practice:
- Build all operations into a dataset worksheet, including joins, aggregations, sorts, or filters.
- Make sure to limit the dataset to only columns needed. (See Below Section — Only use columns needed).
- Make sure to filter down the dataset to only rows needed. (See Below Section — Decrease Row Count).
- Turn on Materialization (See docs: Sigma Materialization) and set a refresh schedule.
Only Use Columns Needed
In columnar databases, data is stored and organized across partitions as columns and not rows. This means the fewer columns selected means the fewer partitions, and therefore less data that has to be scanned. It’s important to note that Sigma is more performant when you select only the columns you actually need to work with. Loading all the columns of a table, or ones that just don’t get used in your analysis, will hurt performance. Begin all your workbooks by only loading needed columns, or deleting the ones you don’t use within them. Don’t worry about forgetting to add a column when you first create a workbook element. You can always add more columns after the fact.
Decrease Row Count Using Filters
The fewer rows queried means less data has to be scanned and processed in your database. This means fewer rows in your workbook will result in better performance. You can minimize the number of rows being queried from a workbook by using filters. Applying filters early on in your work will ensure that your workbooks will be subsequently more performant.
Read more: Creating Sigma Filters
Using Relative Date Filters
One way to ensure that your data is being filtered down to only the data you need is to use relative date filters. If your use case only requires you to use the most recent 90 days of data, a relative date filter will ensure that Sigma is only loading the most recent 90 days of data. Using relative date filters saves you from querying more data than is necessary while also saving you the hassle of constantly updating your datetime filter.
Date Filters can be applied by adding a filter to any date type field, then selecting the filter type. An example of setting up the filter to always filter for the most recent 90 days is below:
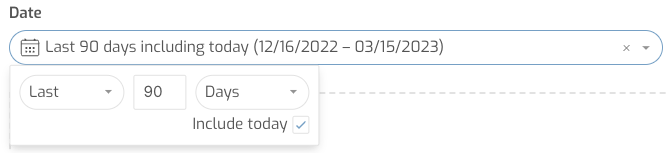
Required Filters
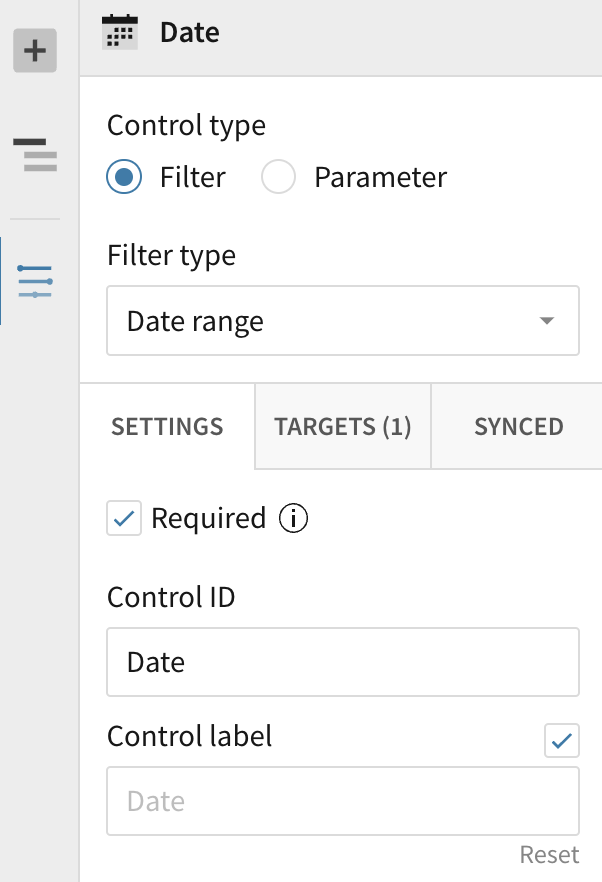
Loading all the data for a workbook upon initial load might result in waiting a significant amount of time for it to load if the dataset is too large or queries are complex. Additionally, you may want to enforce certain filters on large datasets or complex queries for better performance. Sigma’s “Required Filters” give you the ability to enforce filters so that not all data is loaded for a workbook at any given time. All that is required is to select the required checkbox in the filter control settings. If a filter value is not selected, all elements with that filter as a dependency will not load/render.
Linking Tables
With links, Sigma gives you the ability to join or link tables together without adding all the columns needed with the initial join. In practice, you can join a single key field from one table to your base table, but still give your users the option to add the columns they need when they are working with the dataset. This means that if your second table has 400 columns that may be needed by your users, you don't have to add all 400 columns via a join — doing so would not be a best practice and would probably result in poor performance. Instead, you simply add the key field via a link. When using a linked dataset in a workbook, users can add the columns they need from the linked table with a couple of clicks.





